LangChain + ServiceNow = Intelligent Process Orchestration
- Sanjay Raina
- Nov 24, 2024
- 13 min read


Large Language Models (LLMs) and Generative AI are among the most transformative technologies in recent times. These systems leverage deep learning algorithms to understand, generate, and interact with human language in ways that were unimaginable just a decade ago. From chatbots to creative tools, their applications are reshaping industries and pushing the boundaries of artificial intelligence.
In this article, we describe how the power of LLMs can be combined with workflow automation tools to build a new breed of cognitive process automation capabilities, enabling the automation of activities that previously relied on specialist human expertise and reasoning ability.
We will build a sample integration between LangChain and ServiceNow. LangChain is a versatile framework for developing LLM applications, and ServiceNow is a de facto standard process automation tool found in most enterprises, large and small.
LangChain: The Swiss army knife for building LLM solutions
Large language models are impressive in generating human-like text and understanding complex language patterns. LLMs can search, translate, summarize, and respond to questions and generate new content, including text, images, music, and software code.
However, on their own, they have some limitations and need additional capabilities when solving real-world problems in a business context. These limitations include:
Gaps in knowledge: even though the scale of training data used by LLMs is vast, there are gaps. The training data used generally has an end date and is limited to data in the public domain. So, when asked about topics beyond the cutoff date or data that is private to an organisation, the LLM tends to hallucinate.
Token constraints: there is a limit on the amount of input tokens when LLMs process a query. E.g., the limit for GPT3.5 is 4,096 and for GPT4 it is 32,768 tokens. So, asking questions longer than the token limit is likely to return an error.
Inability to follow rules and actions: while LLMs are great at predicting the next word in a sentence, they lack any inherent logical reasoning capability and cannot perform actions such as searching and complex calculations.
Lack of memory: LLMs struggle with tasks that require retaining information over a long period or making connections between different pieces of information. Without a memory component, these models struggle to provide accurate responses to questions that require context or previous knowledge.
Inability to process structured data: LLMs are great at processing unstructured text but can struggle with structured, tabular data.
Enter LangChain, a flexible framework for building LLM-based applications. It simplifies the process of connecting LLMs like OpenAI's GPT models with external data sources, tools, and APIs to build powerful, context-aware applications, overcoming the limitations described above.
There are many excellent resources available that describe the LangChain framework and its features, including the LangChain documentation. Here, we summarise its key capabilities.
Model I/O: the core building block of LLM applications. LangChain enables you to integrate with a variety of models, including Chat Models that use chat messages as input/output rather than plain text. With Prompt Management one can develop sophisticated prompts to elicit specific outputs from language models. Output parsers enable the generated output to be presented in various formats.
Chain composition: enables linking of tasks and primitive functions into pre-defined, reusable compositions that serve as building blocks for application development. Chains allow powerful constructs to be built using pipelines of form such as:
Chain = Prompt() | LLM() | OutputParser()
Memory Management: allows LLMs to retain context over extended interactions, enabling multi-step conversations and workflows, essential for building context-aware applications.
Retrieval: Enables access to and interaction with untrained data to augment the knowledge available to LLMs. This includes utilities to load documents from various sources and to split the text data. It also includes embedding capabilities to convert, store, and index vector representations of text data.
Tools and Agents: enable integration with external APIs and services, including databases and SaaS systems. Agents use LLMs to determine actions to take to complete a task.
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) refers to the process of incorporating additional data as context into a prompt to the LLM. This enables LLMs to go beyond the limitations of training data and respond to queries relating to topics that are not in the public domain or beyond the training cutoff date.
As shown below, a RAG system has two main sub-systems.

First, it ingests data and stores it in a vector store. Due to the limitation in the length of tokens that can be processed by LLMs, the documents need to be split into smaller chunks. The text chunks are then transformed into vector embeddings and stored in a vector database. Embeddings are essentially vector representations of the meaning of words in context. This process is known as indexing.
The second sub-system then uses the stored vector data as lookup to match against the user query. This lookup of matching data is what is referred to as "retrieval" in RAG, and it provides the extra context in the prompt to the LLM. The combination of matched document data and the query used as context enables the LLM to generate the final answer. The "augmented generation" part of RAG corresponds to the ability of LLMs to combine retrieved data as context with pre-trained data to return a response to the user.
AI Agents
Agents are used to enable language models to perform a series of actions. Unlike chains, in which a predetermined sequence of actions is performed, Agents allow LLMs to be used as a reasoning engines. An Agent can be thought of as a chain that uses the LLM to decide which actions to take next.
As shown below, Agents rely on a runtime capability called Agent Executor. This is what executes the actions.

The agent framework also relies on a collection of Tools, that behave like functions, accomplishing tasks as directed. Langchain provides a wide range of tools, performing a variety of functions, including web scraping and code generation.
ServiceNow RAG and Agent using LangChain
ServiceNow is a premier platform for digital workflow automation, asset management, incident tracking, and customer service management. Organizations rely on it for automating business processes and streamlining operational activities.
Key capabilities of ServiceNow include:
Process Workflows: define end-to-end workflows across departments, from HR to IT, using visual tools and templates.
Incident and Task Management: track and resolve incidents efficiently, prioritizing tasks based on urgency and resource availability.
Integration Hub: connect with numerous third-party systems, including CRM, ERP, and cloud solutions, enabling a unified data environment.
AI and Analytics: incorporate AI and machine learning capabilities into automation capabilities.
ServiceNow, like many companies, is investing heavily in augmenting its product lineup by leveraging Generative AI and LLMs. In the future, this may result in new capable features in the product. However, our interest here is to use ServiceNow just as an external data source and system of action for LLMs. We will use LangChain to integrate with ServiceNow and build:
A RAG system to enable us to chat with ServiceNow knowledge base.
A ServiceNow Tool and its use in an Agent to orchestrate workflow actions with the help of LLM and incident data.
Let's start.
Prerequisites
The code used in the examples below is available on Github here: LangChain ServiceNow repository.
You will need.
A Python environment. I prefer using Jupyter Notebooks as I like the responsive way of experimenting with and building code fragments. Make sure to install Langchain and other dependent modules as required.
pip install langchain
OpenAI LLM: Get an OpenAI key by registering with the OpenAI developer platform.
Disclaimer: Please bear in mind that you may incur charges when calling the APIs, depending on the models chosen and usage.
ServiceNow: Get a ServiceNow personal developer instance by registering with the ServiceNow developer portal. You will need to create a user that the API can use to read and write table data.
Environment variables: Create a .env file and add the OpenAI API key and the ServiceNow instance values as environment variables. The contents of the file should look like this:
OPENAI_API_KEY=sk-*****
SERVICENOW_INSTANCE_URL=https://dev*****.service-now.com
SERVICENOW_INSTANCE_USERNAME=******
SERVICENOW_INSTANCE_PASSWORD=******ServiceNow RAG
The first step in building a RAG is to have a document loader. There are a number of loaders available for Langchain as described on this page: Document Loaders. There isn't one available for ServiceNow, but creating one should be easy. Just follow the instructions on this page: How to create a custom Document Loader.
The document loader contains a lazy_loader function that calls the ServiceNow table API as follows:
headers = {"Content-Type": "application/json", "Accept": "application/json"}
url = self.instance_url + \
"/api/now/table/" + self.table + "?sysparm_limit=10&sysparm_query=" + \
self.query + "&sysparm_fields=" + self.fields
response = requests.get(url, auth=(self.instance_username,
self.instance_password), headers=headers)
data = response.json()And then yields the queried data as a series of Document objects.
pattern = re.compile('<.*?>')
for rec in data['result']:
doc = "\n"
for fld in fldarr:
doc += fld + ":" + rec[fld] + "\n"
content = re.sub(pattern, '', doc)
yield Document(page_content=content,
metadata={"line_number": line_number, "source": self.instance_url},
)Once the document loader is created, we can build the main RAG script.
We start with loading the environment variables and importing the required modules.
from dotenv import load_dotenv
load_dotenv() # take environment variables from .env
from langchain_openai import OpenAIEmbeddings
from servicenow import ServiceNowLoader
from langchain.vectorstores import FAISSWe then load the ServiceNow "documents" using the document loader we just created. In this case we are loading a subset of the knowledge base articles.
table = "kb_knowledge"
query = "short_descriptionLIKEsmartcool"
fields = "short_description,text"
loader = ServiceNowLoader(table, query, fields)
docs = loader.lazy_load()
for doc in docs:
docarr.append(doc)Next, we create Embeddings from the loaded document and store them in the vector store.
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docarr, embeddings)We then create the Retriever.
retriever = vectorstore.as_retriever()Next, we create a chain to incorporate the retrieved context in the Chat.
from langchain.chains import ConversationalRetrievalChain
from langchain_openai import ChatOpenAI
qa_chain = ConversationalRetrievalChain.from_llm(
ChatOpenAI(),
vectorstore.as_retriever(search_kwargs={'k': 3}),
return_source_documents=True
)Finally, we test the RAG by asking a question, using the right prompt.
query = "You are a customer service agent. Draft an email to a customer on how to use the SmartView Camera."
result = qa_chain({'question': query, 'chat_history': chat_history})
print('Answer: ' + result['answer'] + '\n')The RAG should respond with something as follows:
Answer:
Subject: Guide on Using the SmartView Camera Feature in Your SmartCool Refrigerator
Dear Valued Customer,
I hope this email finds you well. We appreciate your interest in utilizing the SmartView camera feature in your SmartCool refrigerator. Here is a step-by-step guide to help you effectively use this feature:
1. Touch View Inside on the SmartCool fridge display screen.
2. You can ...
---
5. To access the Shopping List, touch the MENU button on the display screen and then select Go to Shopping List.
By following these steps, you will be able to make the most out of the SmartView camera feature in your SmartCool refrigerator.
If you encounter any difficulties or have any further questions, please do not hesitate to reach out to us. Our customer service team is here to assist you with any queries you may have.
Thank you for choosing our SmartCool refrigerator. We hope this guide enhances your experience with our product.
Best regards,
[Your Name]
[Customer Service Representative]
[Company Name]So, what happened? The RAG used the chat query to retrieve a set of matching documents (text) from the vector store and then used the matched text as context along with the query in the prompt to the LLM to generate the response that we see above.
ServiceNow AI Agent
In the previous RAG example, notice that the chain is static. It uses the external knowledge base as a reference and always follows the same path, albeit coming up with creative answers. Imagine if we had multiple data sources and complex workflows and we wanted the LLM to traverse the right path in the workflow depending on the query and the external data available. That's exactly what an Agent in LangChain can do.
Let us now build a reasoning agent that is able to use LLM to decide what actions to take next without adhering to a predetermined chain. As with RAG, there are a lot of Tools already available in LangChain but none for ServiceNow, so we'll create one based on the instructions on this page: How to create Tools.
You can find a sample ServiceNow Tool in servicenow_api_wrapper.py in the Github repository.
The Tool defines two functions: get_incidents() and create_incident().
The get_incidents() function uses the ServiceNow GET API call to return a list of incidents.
def get_incidents(self, query: str) -> str:
headers = {"Content-Type": "application/JSON",
"Accept": "application/json"}
url = self.url + "/api/now/table/incident?sysparm_limit=" + \
str(self.limit) + "&sysparm_query=" + sysparm_query + \
"&sysparm_fields=" + self.fields
response = requests.get(url, auth=(self.username, self.password), headers=headers)The create_incident() function uses a POST request to create an incident using the parameters.
def create_incident(self, query: str) -> str:
url = self.url + "/api/now/table/incident"
headers = {"Content-Type": "application/json",
"Accept": "application/json"}
response = requests.post(self.url, auth=(self.username, self.password), headers=headers, data=query)
return responseOnce we are done with the Tool, we can create the Agent (see test_agent.ipynb). As usual, we need to load the relevant modules and source the environment variables first, including the OpenAI API key.
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.tools import Tool
load_dotenv()It is important to define prompts that guide the LLM in choosing the right tool. Here is an example prompt telling the Agent how to use the tool to get Incident records.
SERVICENOW_GET_RECORDS_PROMPT = """
This tool is a wrapper around the ServiceNow table API, useful when you need to search for records in ServiceNow.
Records can be of type Incident, Change Requests or Service Requests.
The input to the tool is a query string that filters results based on attribute value.
For example, to find all the Incident records with Priority value of 1, you would
pass the following string: priority=1
"""
SERVICENOW_INC_CREATE_PROMPT = We need to define the tools next. In addition to the ServiceNow tool we just built, we also load a built-in tool for web-scraping, the DuckGoGoSearch Tool.
from snow_api_wrapper import ServiceNowAPIWrapper
from langchain.utilities.duckduckgo_search import DuckDuckGoSearchAPIWrapper
servicenow = ServiceNowAPIWrapper()
duckduck_search = DuckDuckGoSearchAPIWrapper()Next, create the toolkit, which is simply a list of tools. Notice how we are using the predefined prompts as the description of the tools to help the LLM.
tools = [
Tool.from_function(
name = "ServiceNow_Get",
func=servicenow.get_incidents,
description=SERVICENOW_GET_RECORDS_PROMPT
),
Tool(
name = "Search_DuckDuckGo",
func=duckduck_search.run,
description="useful for when you need to answer questions about current events. You should ask targeted questions"
)
]Next, let's create the Agent Executor, using the LLM, agent and standard prompt as input.
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)OK, that's the agent done. Let's ask it a question.
response = agent_executor.invoke({"input":"You are a technical support analyst. Retrieve a list of ServiceNow incidents of priority 1 and for each incident, use its description to find a solution on the web."})The Agent responds as follows. It determines the most appropriate tool is ServiceNow_Get and lists out the incidents.
> Entering new AgentExecutor chain...
Invoking: `ServiceNow_Get` with `priority=1`
number: INC0000060
short_description: Unable to connect to email
description: I am unable to connect to the email server. It appears to be down.
number: INC0009002
short_description: My computer is not detecting the headphone device
---Truncated---It then uses the Search agent to search for solutions on the web.
Invoking: `Search_DuckDuckGo` with `solution for unable to connect to email server`
In Control Panel, search for and open the Mail icon. On the Mail Setup - Outlook window, click Email Accounts. On the Account Settings window, ....
Invoking: `Search_DuckDuckGo` with `solution for computer not detecting headphone device`
---Truncated---Finally, it summarises the solutions in a nicely readable list:
1. **Incident: Unable to connect to email**
- **Solution:** To fix the issue of being unable to connect to the email server, you can try the following steps:
- Check the Incoming mail server and Outgoing mail server settings.
- Change the view type to Large icons and click on Mail (Microsoft Outlook).
- Add an Email Account Again.
- Use encryption method as SSL/TLS.
2. **Incident: My computer is not detecting the headphone device**
- **Solution:** To resolve the issue of the computer not detecting the headphone device, you can try the following:
- Check if the headset mic is disabled in Windows 10.
- Remove and re-add the headphones.
- Run a troubleshooter.
- Manually set Headphones as the default device.
---Truncated---Now let us try a different prompt to create an incident.
response = agent_executor.invoke({"input":"You are a technical support analyst and a customer has just called about a faulty laptop. Create a ServiceNow incident for this issue."})And here is the response. As before, the agent determines that the most appropriate Tool for this query is ServiceNow_Create.
> Entering new AgentExecutor chain...
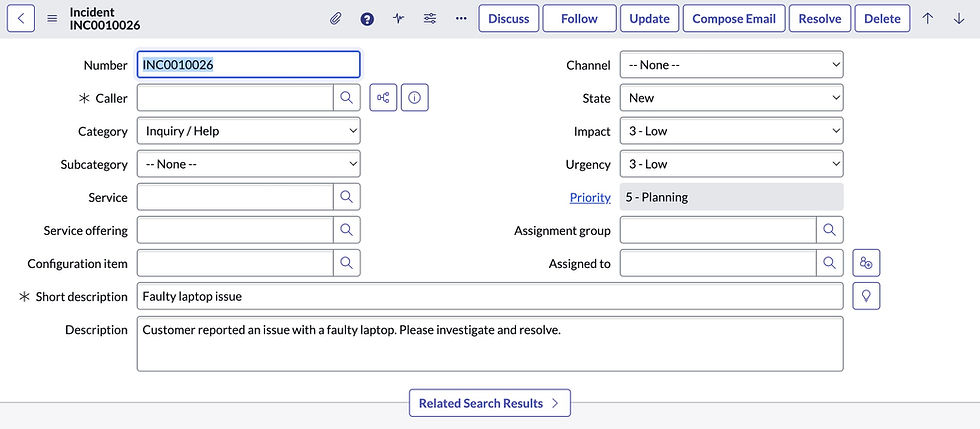
Invoking: `ServiceNow_Create` with `{"short_description": "Faulty laptop issue", "description": "Customer reported an issue with a faulty laptop. Please investigate and resolve."}`
<Response [200]>I have successfully created a ServiceNow incident for the faulty laptop issue.The agent called the tool with appropriate field values for short_description and description.
And here's the incident as created in ServiceNow.
A better UX with Streamlit
The way we have tested queries so far, from within the code itself is not a great user experience. Let's fix that by using another of my favorite tools—Streamlit. It's a great tool for creating interactive web applications with just a few lines of Python code. We will use it to create a simple yet engaging chat interface.
I won't reproduce any of the code here, as we will reuse what has already been described in the previous sections. Just make sure you have the appropriate modules installed and loaded.
pip inslall streamlitThe code for this app is available in st_app.py.
We have added the following additional features to this app.
Display retrieved incidents in a table using the AgGrid module allows us to display the retrieved incidents in a table.
Ability to plot graphs using the plotly package.
Analyse retrieved data and perform actions using the Pandas Dataframe tool.
Let us see this in action. You can launch the chatbot app as follows:
streamlit run st_app.pyThe app will launch in a browser tab and should look something like below. The sidebar on the left allows you to choose a few options, and the main canvas contains the chat interaction.

Let us try out a few questions. We'll try the RAG use case first, leave the other options unchanged, and type the following question in the chat input:
You are a customer service agent. Draft an email to a customer on how to use the SmartView Camera.You should see the bot respond with something like:

As before, the app first retrieves the matching documents from the ServiceNow knowledge base and passes this on to the LLM as context to generate the email.
Next, let us try the Agent from the left sidebar. Leave the other options unchanged for now. Choose the "Action" radio button option for the type of chat. You should see a list of incidents retrieved from ServiceNow. Note that there is no LLM or LangChain used yet in this case. It simply calls the ServiceNow REST API and displays the results using AG Grid.

Selecting a row from the table will display the chat interaction container below the table, where you can ask a question.

We are asking the agent to use the incident as the context and search for a solution on the web. The agent response should look something like below.

Observe how the agent used the incident details and passed them to the Search tool. You can see the input and output of the search tool in the collapsed container. The completed response shows the resolution as above.
Finally, let us try the ability of the agent to use another tool to analyse the data in the table and plot a graph. It will use the Pandas dataframe tool and the Plotly package to plot.
Select the Analyze radio button option from the left sidebar. Enter your query as follows.

The agent will get into action, this time generating plotly code to draw the graph as shown below.

You can see the code that the agent generated if you expand the containers above the graph. Pretty neat, eh!
Using this interface, one can experiment further with the code and different prompts.
Wrap up
We've only scratched the surface in this article, but one can imagine the incredible potential and possibilities of using LLM technologies for business process automation. This is an active area of development, and new framework capabilities are emerging on a regular basis, opening new avenues and approaches for developing intelligent automation applications.
One such example is LangGraph, an orchestration framework built on top of LangChain that incorporates a persistence layer to enable human-in-the-loop interactions. LangGraph Studio adds low-code, visual ability to develop complex agentic applications much more easily than before. Visualising agent graphs helps application developers understand the complex data interactions in agentic applications.
We live in interesting times indeed!


Comments